Terraform stands as one of the most recognized and utilized tools for managing your infrastructure as code (IaC). It not only enables you to define your infrastructure in a declarative manner but also facilitates handling changes through the same development workflow utilized for software: encompassing version control, code review, testing, and employing CI/CD pipelines for deployment.
When facing the challenge of managing multiple environments, I started digging into Terraform features to implement a solution that would have met all of my requirements.
In this article, we will explore the different options and their pros and cons. I will also propose a solution that I believe is the best one, in my scenario, to manage multiple environments in Terraform.
Requirements
What I wanted to achieve was to have a solution that would have met the following requirements:
-
Manage multiple environments in the simplest way possible
-
Terraform code
- Use only one repository for all environments
- Minimize code duplication
- Simple promotion of changes through environments
-
Terraform state files
- Store state on a remote backend
- Use a single state file per environment
-
Per-environment customizable resources configuration
- Different resource types / SKUs
- Different count of deployed units
-
Compatibility
- Compatible with backends that don’t support Terraform workspaces (e.g. GitLab, S3)
-
Development Workflow
- Allow code review before deployment
- Handle deployment in a unified and inspectable way through CI/CD pipelines
Managing State - The Terraform Workspaces Feature
Terraform workspaces are the native feature designed to solve this problem. However, I had to discard this option quite early because this feature is not supported by most of the backends, forcing you to use Terraform Cloud and not others as I wanted (e.g. GitLab).
Also, while I experimenting, I didn’t like that all the environments are stored in the same state file. This is not ideal for security reasons. If you want to give access to a specific env to a specific user, you can’t easily do it.
Code Organization: Directories or Branches
This was one of the first and most important decisions to make.
When searching for this topic on the internet, you will find two main approaches to organize Terraform code: directory-based or branch-based.
In the directory-based approach, you have a single repository with a directory for each environment.
envs
├── dev
│ ├── main.tf
│ ├── variables.tf
│ └── outputs.tf
├── staging
│ ├── main.tf
│ ├── variables.tf
│ └── outputs.tf
└── prod
├── main.tf
├── variables.tf
└── outputs.tf
The problem of this approach is that you have to duplicate the code for each environment and then maintain it aligned. This is less than ideal since it increases maintenance overhand and possible mistakes - it is easy to forget to copy one or more files when the codebase grows. CRs also becomes more messier and difficult to review.
Moreover, I also didn’t like how you would have to promote changes through environments. The entire folder content would have to be copied over the next environment folder resulting in bloated diffs during code reviews and more complicated rollback procedures when everything is integrated in CI.
That’s why I dismissed this approach in favor of a branch-based approach.
With the branch-based solution you have one directory and a single reference code. The branches track the environments state and are easy to merge one in the other.
Pros:
- Unique codebase - easier maintenance
- Promotion of changes between environments consist of a merge request, allowing for code review and pre-deployment inspection of Terraform plan (from the CI pipeline artifacts)
- Effortless rollback by reverting the merge commit
- Re-run the deploy pipeline over a branch to ensure the infrastructure is in the desired state for that environment
Customize Resources Configuration Per Environment
The next challenge was to customize the resources configuration per environment. For example, I wanted to be able to deploy a different VM size in the environments.
I got the inspiration from this talk and this article to use maps variables and count property.
The idea is to define a map variable anytime you want to customize a value based on the environment. Also, use the count property if you want to deploy a different number of resources per environment - eventually zero if you want to skip a specific environment. I liked this “map approach” for its clarity in the values specified for each env: <env-name> = <value>.
Then, I organized them in a separate module to better scale when the number of customized values grows. Into the config directory you could create other modules like subscription, gloabls, pricing, etc.
project
├── config
| └── environment
| ├── main.tf
| ├── variables.tf
| └── outputs.tf
└── env
├── main.tf
├── variables.tf
└── outputs.tf
# config/environment/variables.tf
variable "env" {
description = "short name of the environment"
}
# config/environment/main.tf
vm_size = {
dev = "Standard_B1ms"
stg = "Standard_D2ds_v5"
prd = "Standard_D2ds_v5"
}
vm_count = {
dev = 1
# if you didn't want to deploy the machine in dev
# dev = 0
stg = 2
prd = 2
}
Export the values as outputs of the module for later use:
# config/environment/output.tf
output "vm_size" {
value = local.vm_size[var.env]
}
output "vm_count" {
value = local.vm_count[var.env]
}
The project reads as input the ENV variable from the execution environment:
# env/variables.tf
variable "ENV" {
description = "Short name of environment. Example: export TF_VAR_ENV=dev"
type = string
}
variable "resource_group_name" {
description = "Name of the resource group"
type = string
}
variable "resource_group_location" {
description = "Location of the resource group"
type = string
}
Then, in the main module use the defined variables to customize the resources configuration:
# env/main.tf
module "environment" {
source = "../config/environment"
env = var.ENV
}
resource "azurerm_linux_virtual_machine" "main" {
name = "vm-${var.ENV}-${count.index}"
location = var.resource_group_location
resource_group_name = var.resource_group_name
# here we access the values customized for the current environment
count = module.environment.vm_count
size = module.environment.vm_size
# ...
}
In the example everything depends on the ENV variable. This variable is the equivalent and substitutes the Terraform TF_WORKSPACE variable allowing selecting the usage of a specific workspace. Similarly to the workspace feature, in this case, you can set the ENV variable to to target the desired environment but still using the same codebase. In CICD, the trick is to export env variables conditionally to the branch name: setting the target ENV based on the branch the pipeline is running on.
Backend and state files
Remote state management is essential to keep in a single place your terraform state. In my case, I wanted to use GitLab as a backend through the GitLab Terraform state feature.
The solution to this is to export the TF_HTTP_ADDRESS variable (and related ones) with the URL of the state file that maps to the current env:
export TF_HTTP_ADDRESS="https://gitlab.com/api/v4/projects/<project-id>/terraform/state/${TF_VAR_ENV}"
export TF_HTTP_LOCK_ADDRESS="https://gitlab.com/api/v4/projects/<project-id>/terraform/state/${TF_VAR_ENV}/lock"
export TF_HTTP_UNLOCK_ADDRESS="https://gitlab.com/api/v4/projects/<project-id>/terraform/state/${TF_VAR_ENV}/lock"
Remember, the TF_VAR_ENV variable is set by the CI/CD pipeline based on the branch name and so on the environment in use.
Workflow
Speaking of the git workflow, I wanted to adopt a feature-based workflow, so similar to the GitHub flow but also resembling the GitOps paradigm for deployments.
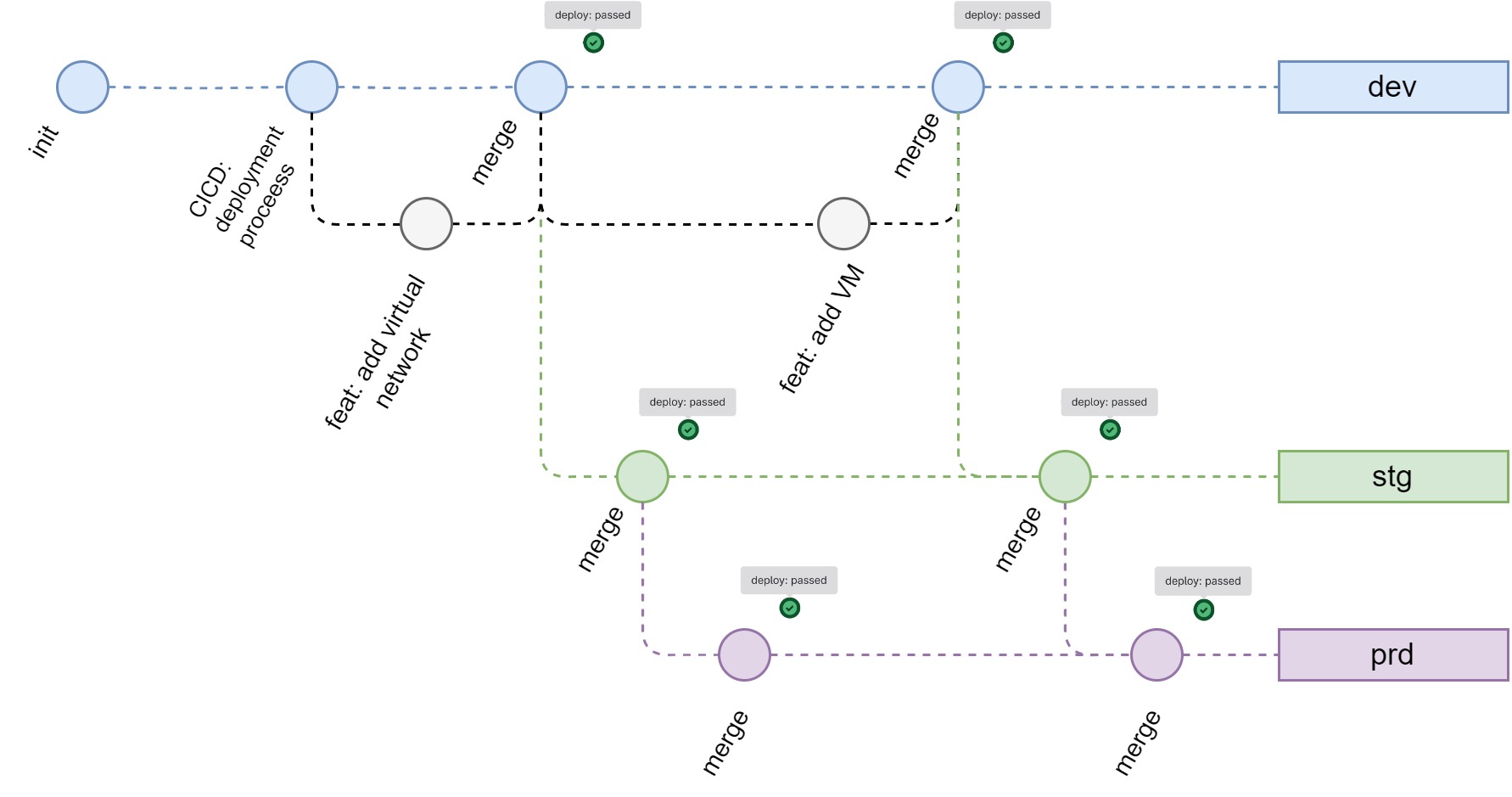
Each branch corresponds to an environment, with dev being the main branch. The stg and prd branches receive changes from the dev branch through “propagation” merge requests.
For every merge request, the CI pipeline is triggered and runs the Terraform plan. The plan is then attached to the merge request as an artifact allowing for its inspection, also for propagation merge requests. The plan is useful together with the MR changes to inspect what will be changed in an environment before doing the deployment.
When the merge request is approved and merged, the next step in the CD pipeline is triggered. This takes care to do a terraform apply in a “deploy” stage.
Back to the example of provisioning a VM, you would create a new branch from the dev, make the changes, and then open a merge request to merge back to dev. With the merge request open, the CI would run a terraform plan against the ideal result of a merge. This would produce a terraform plan that, combined with the diff of submitted changes, would be all what the reviewer would need to inspect the changes. By the approval and then merge of the merge request, the CD pipeline would be triggered and the changes would be deployed to the dev environment.
Conclusion
In this article, I wanted to collect all the major problems I had to solve for an effective multi environment management in Terraform. We have explored the different options and their pros and cons also providing some examples on how to implement this approach.
I hope this article can help you solve your multi-environment management problems in Terraform. If you have any questions or suggestions, please don’t hesitate to get in touch!